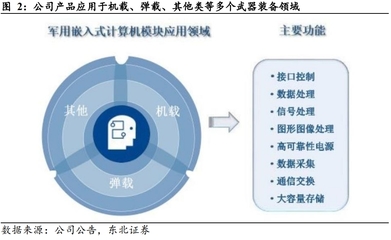
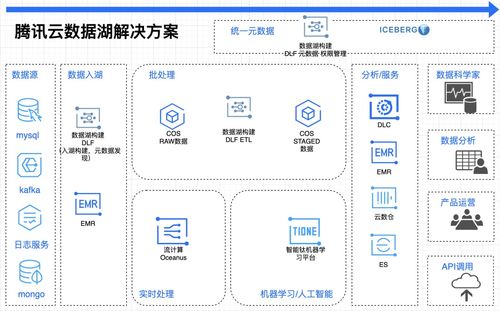
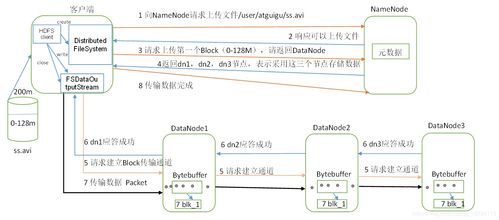
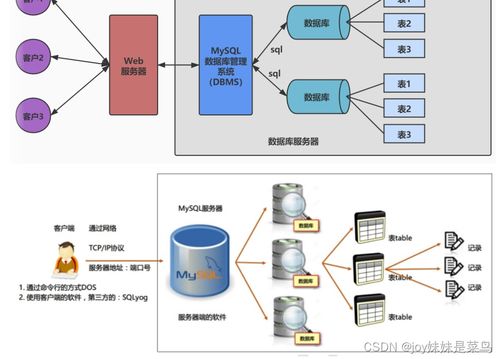
隨著大數據時代的深入發展,數據的來源與形態日益多樣化,結構化數據、半結構化數據與非結構化數據并存,構成了復雜的異構數據環境。針對這一挑戰,專利技術“異構數據處理方法、裝置、服務器及存儲介質”提供了一套系統化的解決方案,其核心思想在CSDN等開發者社區及各類文庫平臺上被廣泛探討,深刻影響著現代數據處理和存儲服務的構建。
一、異構數據處理的核心方法與裝置
該方法通常涵蓋數據接入、解析、轉換、融合與服務等關鍵環節。裝置作為方法的物理承載,集成了相應的硬件模塊與軟件邏輯。
- 統一接入與智能解析:通過設計適配不同協議和接口的接入層,實現對數據庫、API、日志文件、物聯網流數據、社交媒體內容等多源異構數據的無縫采集。裝置內置的智能解析引擎,能依據數據特征自動識別其結構(如JSON、XML、CSV)或內容類型(如文本、圖像、音視頻),并提取關鍵元數據。
- 標準化轉換與質量治理:在解析基礎上,利用預定義的規則模型或機器學習算法,將異構數據轉換為內部統一的中間模型或標準格式(如Avro、Parquet)。此過程同步進行數據清洗、去重、補全與質量校驗,確保下游使用的數據可信、一致。裝置中的數據處理單元專門負責執行這些高計算負載的任務。
- 關聯融合與知識構建:對于來自不同源頭但存在關聯的數據,通過實體識別、鏈接技術進行融合,打破數據孤島,形成完整的對象全景視圖。這為后續的深度分析與知識圖譜構建奠定了基礎。
二、服務器與存儲介質的角色演進
- 服務器的關鍵作用:承載上述數據處理裝置的服務器,已從傳統的通用型服務器向異構計算架構演進。為了高效處理海量非結構化數據(如圖像識別、自然語言處理),服務器普遍集成CPU、GPU、FPGA乃至專用AI芯片,通過算力異構來匹配數據異構,大幅提升處理效率。服務器集群通過分布式計算框架(如Spark、Flink)實現任務的并行與調度,保障了系統的高吞吐與高可用性。
- 存儲介質的策略選擇:存儲介質的選擇直接影響數據處理的性能與成本。現代存儲方案通常采用分層策略:
- 熱數據層:使用高性能SSD或內存,存儲正在被頻繁處理和分析的實時數據。
- 溫數據層:使用高性價比的SAS或大容量SATA硬盤,存儲近期需要訪問的歷史數據。
* 冷數據/歸檔層:采用磁帶庫或對象存儲,存儲極少訪問但需長期保留的數據。
針對異構數據的特點,融合了文件、塊、對象存儲能力的統一存儲平臺正成為趨勢,它能夠在一個系統中為不同類型的數據和應用提供最合適的存儲服務。
三、在數據處理與存儲服務中的實踐價值
- 提升數據服務效能:通過標準化的異構數據處理流程,企業能夠快速整合內外部數據,為業務分析、智能決策提供高質量、統一的數據底座,顯著縮短數據價值變現的周期。
- 優化基礎設施成本:合理的異構計算與分層存儲策略,使得計算和存儲資源能夠根據工作負載動態分配,避免了“一刀切”帶來的資源浪費,實現了成本與性能的最佳平衡。
- 賦能創新應用場景:該技術棧是構建數據湖、數據中臺、AI平臺的核心支撐。它使得企業能夠輕松處理來自IoT設備的海量時序數據、社交媒體中的文本情感數據、生產線上的視覺質檢數據等,從而驅動智能制造、智慧城市、個性化推薦等創新應用。
“異構數據處理方法、裝置、服務器及存儲介質”所代表的技術體系,是現代數據處理與存儲服務的中樞神經。它不僅解決了多源異構數據融合的技術難題,更通過軟硬件協同的架構創新,為各行業挖掘數據資產價值提供了強大引擎。隨著邊緣計算、云原生技術的發展,這一體系正朝著更實時、更智能、更云化的方向持續演進,未來將在更廣闊的數字化場景中扮演不可或缺的角色。